X-VECTORS: ROBUST DNN EMBEDDINGS FOR SPEAKER RECOGNITION[2]是在前一篇论文Deep Neural Network Embeddings for Text-Independent Speaker Verification[1]的基础上的进一步研究。
用TDNN和statistic pooling这两种结构将变长的语音特征输入转化为了定长的embedding,叫做x-vector。
-
用由附加噪音和混响组成的数据增强提高DNN嵌入用于说话人识别的性能,增加数据量并提高鲁棒性。
-
embeddings比i-vector更好地利用大规模训练数据集。
增强对PLDA分类器有益,但是对i-vector提取器没有帮助。
1 Intro
-
DNN最经常被训练为自动语音识别 ASR (automatic speech recognition)的声学模型,然后用于增强i-vector UBM中的语音建模:ASR DNN 后验概率取代GMM的后验概率或从DNN中提取瓶颈特征并跟声学特征相结合。
- 如果ASR DNN在域内数据上训练,进步显著,但都需要转录训练数据,增加了计算复杂性。
-
或者直接优化神经网络以区分说话人,只需要说话人标签进行训练。
-
端到端的系统:一个DNN用于生成嵌入和一个单独训练的分类器去比较它们。有助于使用i-vector的长度标准化、PLDA评分、域适应技术等后端技术。
DNN嵌入表现和训练数据的大小有高度的可扩展性,因此这些系统在大型数据集上利用比较成功。但是最近系统显示只有在公开的说话人识别语料库上训练性能良好。
2 说话人识别系统
包括两个i-vector基线和DNN x-vector
Kaldi
2.1 Acoustic i-vector
基于GMM-UBM的i-vector
帧长为25ms的20维MFCCs,在最长3s的滑动窗口内平均归一化,加上delta和acceleration组成60维的特征向量
[1] 以20维mfcc特征加delta和delta-delta之后组成的60维特征为输入的i-vector系统
2.2 Phonetic bottleneck i-vector
结合了来自ASR DNN的BNF(phonetic bottleneck features)
DNN是个具有p-范数非线性的时延声学结构
ASR DNN在Fisher English corpus上训练,除了倒数第二层换成60维线性bottleneck层
不包括softmax输出层,不需要计算BNFs,DNN有9.2百万个参数
BNFs与上面的20维MFCCs连接加上deltas构成100维特征,其他都跟上面相同
[2] 以20维mfcc特征加delta再加上在Fisher English corpus上训练的60维bottleneck特征组成的100维特征作为输入的i-vector系统
2.3 x-vector
24维滤波器组,帧长为25ms,在长达3秒的滑动窗口内平均归一化。
与基线系统中使用的同样的语音端点检测(SAD,Speech Activity Detection)过滤掉非语音帧。
[1]
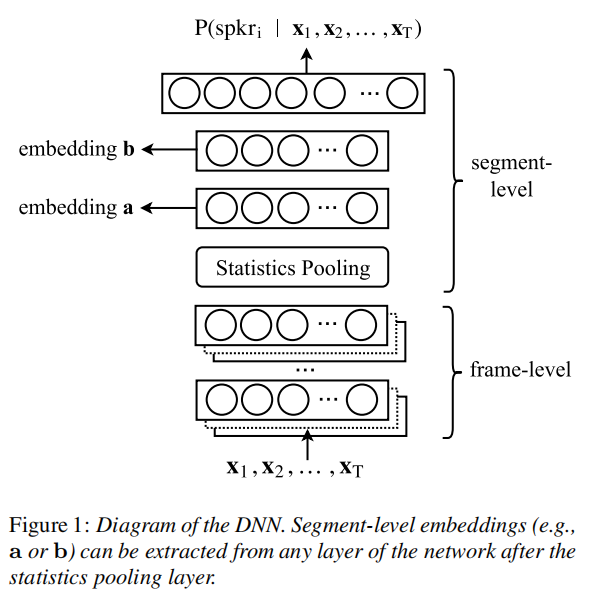
[2]

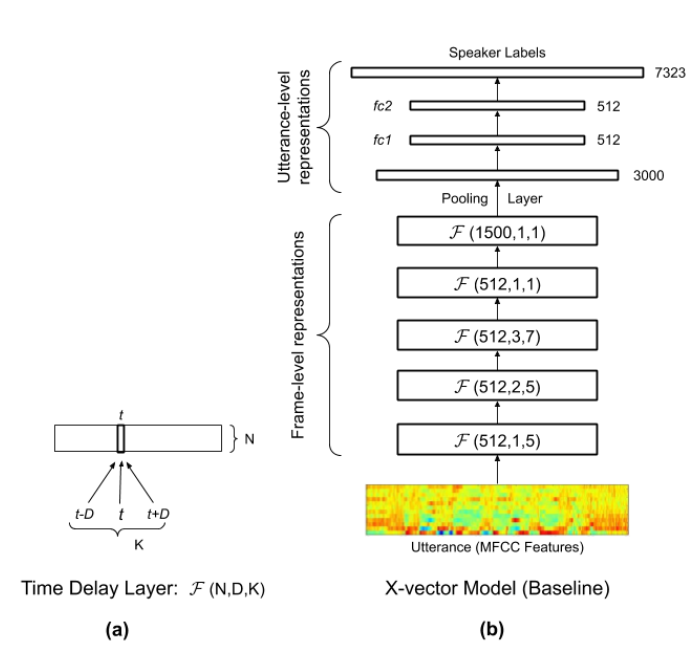
- 输入段包括T帧,前五层在以当前帧t为中心的小时间上下文temporal context语音帧上操作,比如frame3就是在frame2基础上拼接,最后frame3的上下文总共是15帧。用TDNN实现。
- statistics pooling layer统计池层汇总来自frame5层的所有T帧级输出,并计算其均值和方差。统计数据是1500维向量,每个输入段计算一次。这个过程聚合时间维度信息,以便后续层对整个段进行操作。
- 再连接和传播到segment-level layers最后是softmax output layer。nonlinearities都是线性整流函数rectified linear units(ReLUs)。
- 训练后,从segment6层的仿射分量中提取embeddings。不包括softmax输出层和segment7(因为训练后不需要它们),总共有4.2百万个参数。
2.4 PLDA分类器
跟i-vector一样,用LDA进行降维,变成定长的然后后用PLDA作为back-end,用自适应s-norm对分数归一化。
3 实验
3.1 训练数据
3.2 评估
3.3 数据增强
附加噪音和混响,混响reverberation包括将房间脉冲响应(RIR)与音频进行卷积。
3倍增强将原来的clean 训练列表与两个增强副本结合
随机选择:babble、music、noise、reverb
4 结果
4.1 原本系统
i-vector (acoustic) i-vector (BNF) x-vector
4.2 PLDA增强
对三个系统都有明显改进
但是与基线系统比,x-vector系统受益更多。
在SITW上,x-vector系统的错误率略低于i-vector (acoustic),但在大多数操作点上仍然落后于i-vector (BNF)。
在SRE16上,x-vector比i-vector在DCF10^(-2)上保持着14%的优势。
4.3 提取器增强
extractor: UBM/T 或 embedding DNN
i-vector系统中,增强只在PLDA中最有效。
embedding DNN也改进很大,比PLDA有效。
数据增强只对接受过监督培训的提取器有益。
4.4 PLDA和提取器增强
4.5 包括VoxCeleb
5 结论
-
x-vector在SRE16 广东话上显著超过了两个i-vector基线
-
在包含大量增强麦克风语音后,实现了比Speakers in the Wild的最佳基线更低的错误率。
-
x-vector DNN只需要说话人标签来训练,这使得它可能非常适合几乎没有转录语音的领域。
j-vector 文本相关的说话人确认的多任务学习
joint-vector 联合向量
d-vector 说话人确认
deep vector 嵌入码