声纹识别的分类
- 按任务分类
- 声纹验证 speaker verification
- 声纹辨认 speaker identification
- 按文本内容分类
- 文本相关 text-dependent
- 文本无关 text-independent
- 语言相关
- 语言无关
- 文本提示型 text-prompted
声纹识别系统的流程
-
训练阶段
-
识别阶段

预处理

-
预加重
- 原因:语音在高频能量衰减,导致离散傅里叶变换后的信号在高频处的共振峰不明显,不利于特征分析和处理
- 经过一个高频带通滤波器 ,-预加重系数
- 预加重后的语音信号 ,-原始信号
-
分帧 framing
- 原因:语音短时平稳,便于后续信号分析和处理
- 帧长度:通常为10-30ms
- 帧位移:相邻帧信号之间的重叠
-
加窗
- 目的:使时域信号似乎更好地满足FFT处理的周期性要求,减少泄漏
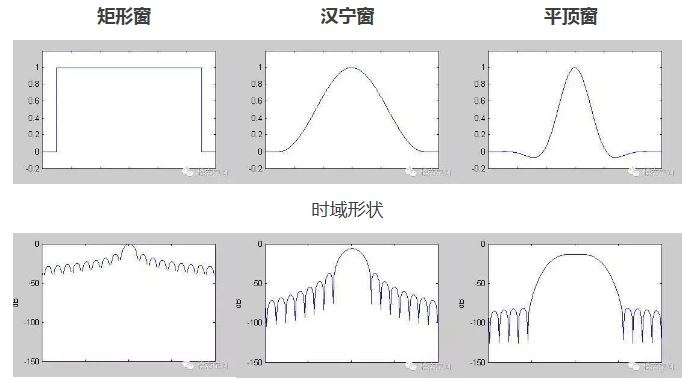
- 目的:使时域信号似乎更好地满足FFT处理的周期性要求,减少泄漏
-
端点检测
- 目的:找到目标语音信号和噪声出现的节点
- 短时过零率 st-ZCR:根据时域信号的连续波形曲线与横坐标的交点个数来确定过零率
- 信号的过零率,-符号函数,窗函数。
特征提取
- 线性预测系数 LPC
- 线性预测倒谱系数 LPCC
- 快速傅里叶变换 FFT
- 梅尔频率倒谱系数 MFCCs
- Fbanks:没有MFCCs的离散余弦变换 DCT
- 动态差分MFCCs
- 动态差分Fbanks
模式匹配
- 深度学习之前的方法
- 动态时间规整 DTW
- 矢量量化 VQ
- 隐马尔可夫模型 HMM
- 高斯混合模型 GMM
- 高斯混合模型-通用背景模型 GMM-UBM
- 高斯混合模型-支持向量机 GMM-SVM
- 联合因子分析 JFA
- i-vector方法
i-vector
- 总体变化空间 total variability space
- 信道补偿
- 类内协方差正则化 WCCN
- 线性判别分析 LDA
- 扰动属性投影 NAP
- 概率线性判别分析 PLDA
- 声纹识别系统
- 基于支持向量机SVM,用余弦核来估计输入数据之间的相似性
- 直接用余弦相似度作为最终决策得分
模式匹配
- 基于深度学习的方法
- 基于ASR-DNN的i-vector方法
- 3D CNN方法
- Deep Speaker识别系统
- j-vector方法
- d-vector方法
- x-vector方法
Deep Speaker识别系统

j-vector
- 用同一个神经网络从语言中识别出文本和从语音中识别出说话人
- GDF/PLDA

d-vector

x-vector
- DNN embeddings
- data augmentation

DenseNet-ICTL

DenseNet-ICTCL

系统性能评价指标
- 识别率
- 等错误率
- 错误接受率
- 错误拒绝率
- 最小代价检测函数
- 曲线